$$\mathcal{L}_{\text{PG}}=\mathbb{E}_{ x_0 \sim \textcolor{blue}{\pi^\text{rm}_{\text{old}}}} \big[ \frac{\hat{\pi}_\theta(x_0)}{\textcolor{red}{\hat{\pi}_\text{old}(x_0)}} A \big],\ \mathcal{L}_{\text{PPO}}=\mathbb{E}_{ x_0 \sim \textcolor{blue}{\pi^\text{rm}_{\text{old}}}} \bigg[ \sum_{n=1}^N \min\big(\frac{\hat{\pi}_\theta(x_0^{(n)})}{\textcolor{red}{\hat{\pi}_\text{old}(x_0^{(n)})}} A, \text{clip}(\frac{\hat{\pi}_\theta(x_0^{(n)})}{\textcolor{red}{\hat{\pi}_\text{old}(x_0^{(n)})}}, 1\pm \epsilon) A \big)\bigg], $$ where the sampling distribution induced by re-masking, $\textcolor{blue}{\pi^{\rm rm}_{\rm old}}$, differs from the approximate likelihood $\textcolor{red}{\hat{\pi}_{\rm old}(x_0)}$, such as the exponential of the ELBO, $\exp L(x_0)$. This mismatch, $\textcolor{blue}{\pi^{\rm rm}_{\rm old}} \neq \textcolor{red}{\hat{\pi}_{\rm old}(x_0)}$, introduces bias into RL training and can degrade performance.
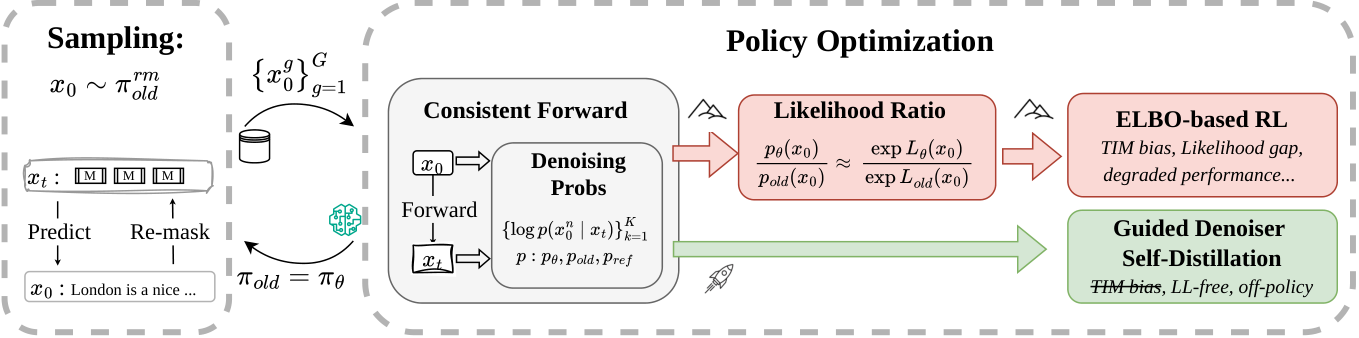
In this work, we propose Guided Denoiser Self-Distillation (GDSD) avoid this issue by directly distilling the denoiser of dLLMs from an advantage-guided self-teacher, derived from the closed-form optimum of reverse-KL regularized RL. We evaluate on planning, math, and coding benchmarks with LLaDA-8B and Dream-7B, where GDSD matches or outperforms prior state-of-the-art ELBO-based methods with a more stable training reward dynamics.
GDSD follows ELBO-based methods: randomly masking sequences and compute the denoising probabilitites $p(x_0|x_t)$. Unlike ELBO-based methods, GDSD directly matches the denoising logits of dLLMs to the target denoiser $p^*$, an advantage-guided self-teacher:

GDSD is a principled self-distillation procedure equivalent to reverse-KL regularized RL $$\max_{\pi} \; \mathbb{E}_{x_0 \sim \pi} [ \psi A(x_0) - D_{{\text{KL}}}(\pi \| \pi_{\text{old}} ) - \beta D_{\text{KL}} ( \pi \,\|\, \pi_{{\text{ref}}} ) ]$$, which has the closed-form optimum $\pi^{*}(x_0) \propto \pi_{\text{old}}(x_0)^{{(1 - \beta)}} \cdot \pi_{{\text{ref}}}(x_0)^{{\beta}} \cdot \exp\big( \psi A(x_0) \big)$, and the optimal denoiser: $$ p^*(x_0|x_t) = p_\text{old}^\text{ref}(x_0|x_t) \cdot \exp(\psi A(x_0) - A_t(x_t)),$$ where the mixture denoiser $p_\text{old}^\text{ref}(x_0|x_t)\propto p_{\text{old}}(x_0|x_t)^{1-\beta} p_{\text{ref}}(x_0|x_t) ^{\beta}$. GDSD employs normalization-free logit matching to approximate $p^*$, successfully avoiding estimating the intractable likelihood and normalization constant $A_t$. Thus, GDSD is efficient and stable.
Our method GDSD achieves more stable training than ELBO-based methods.
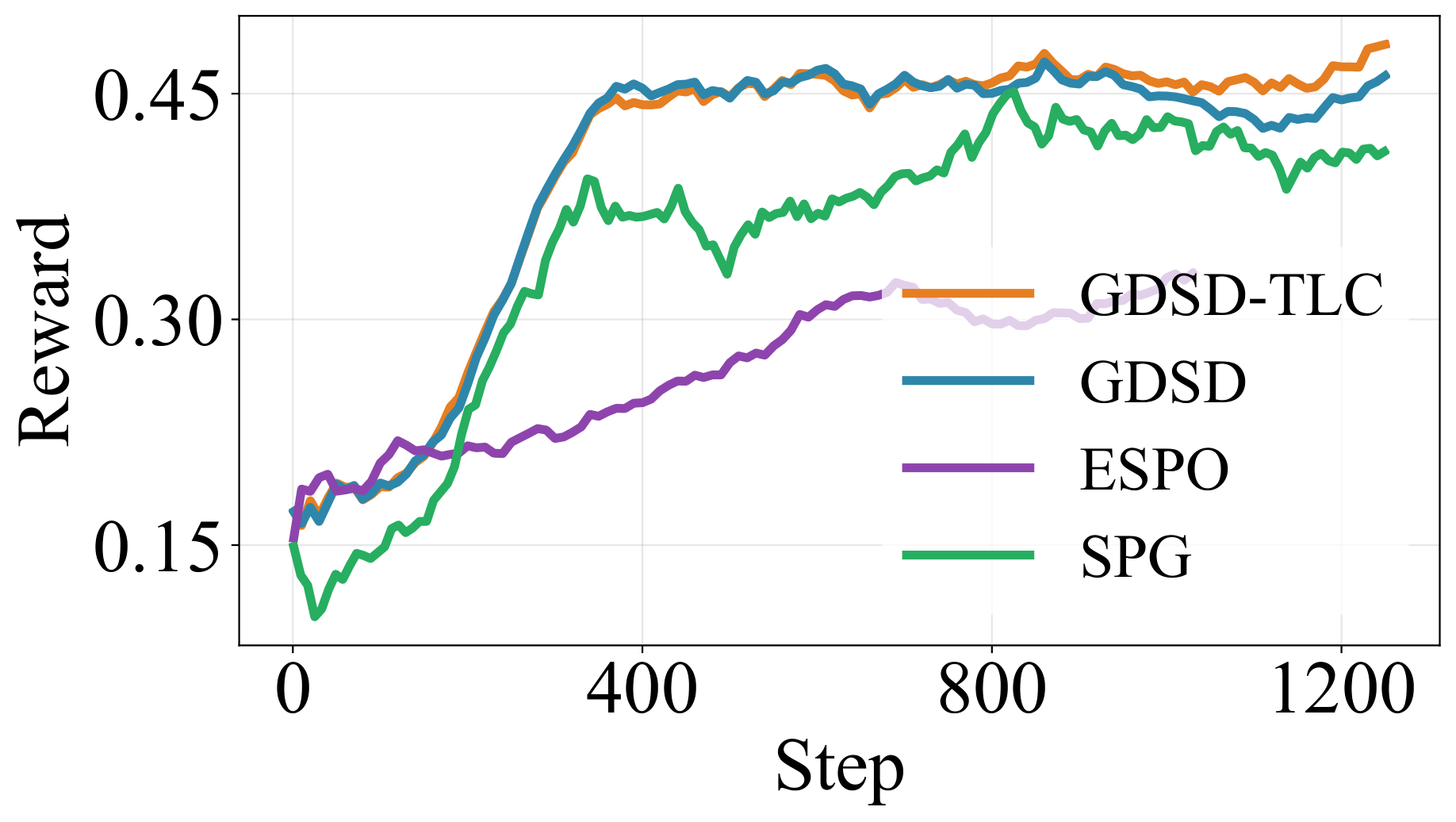
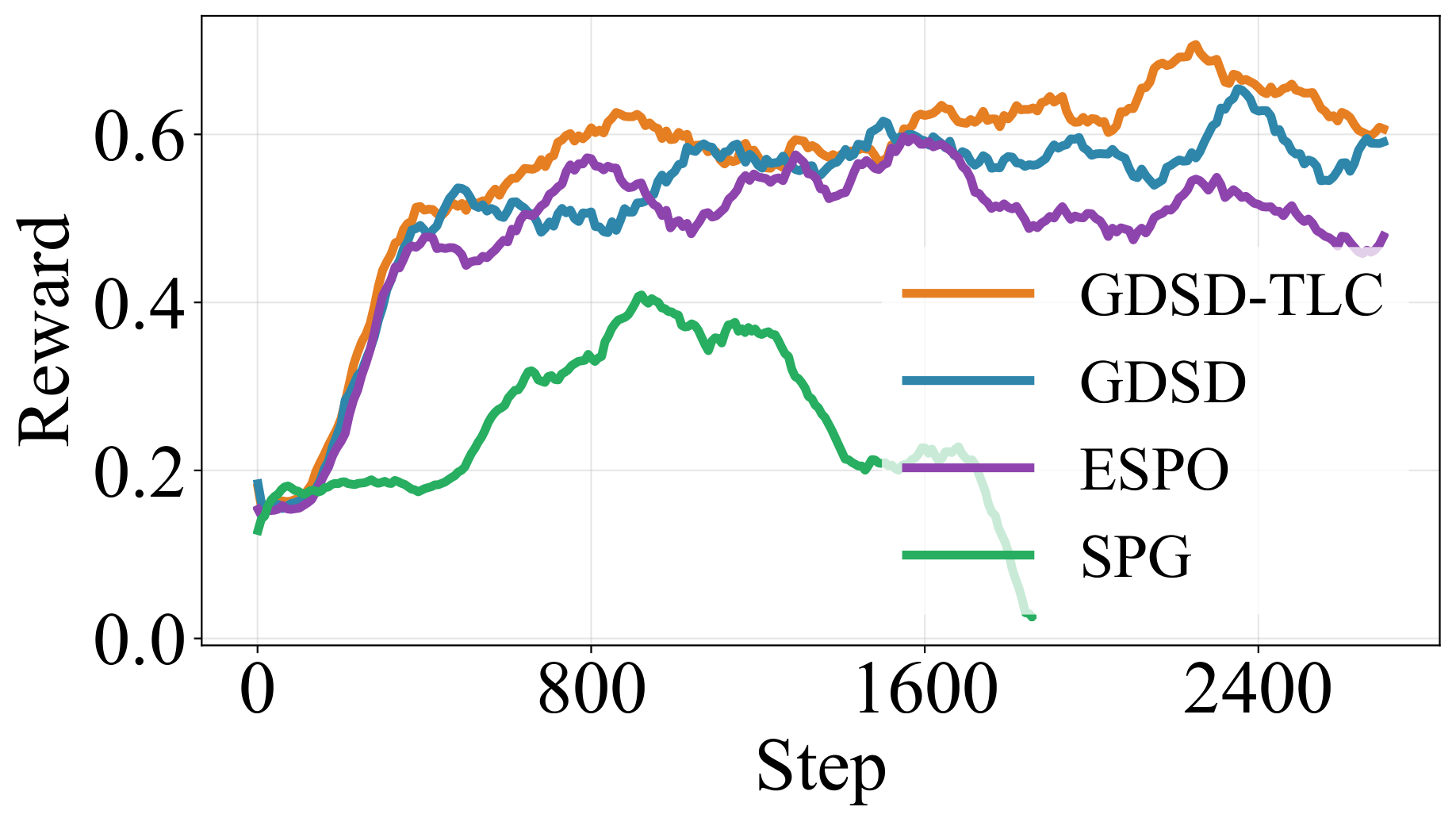
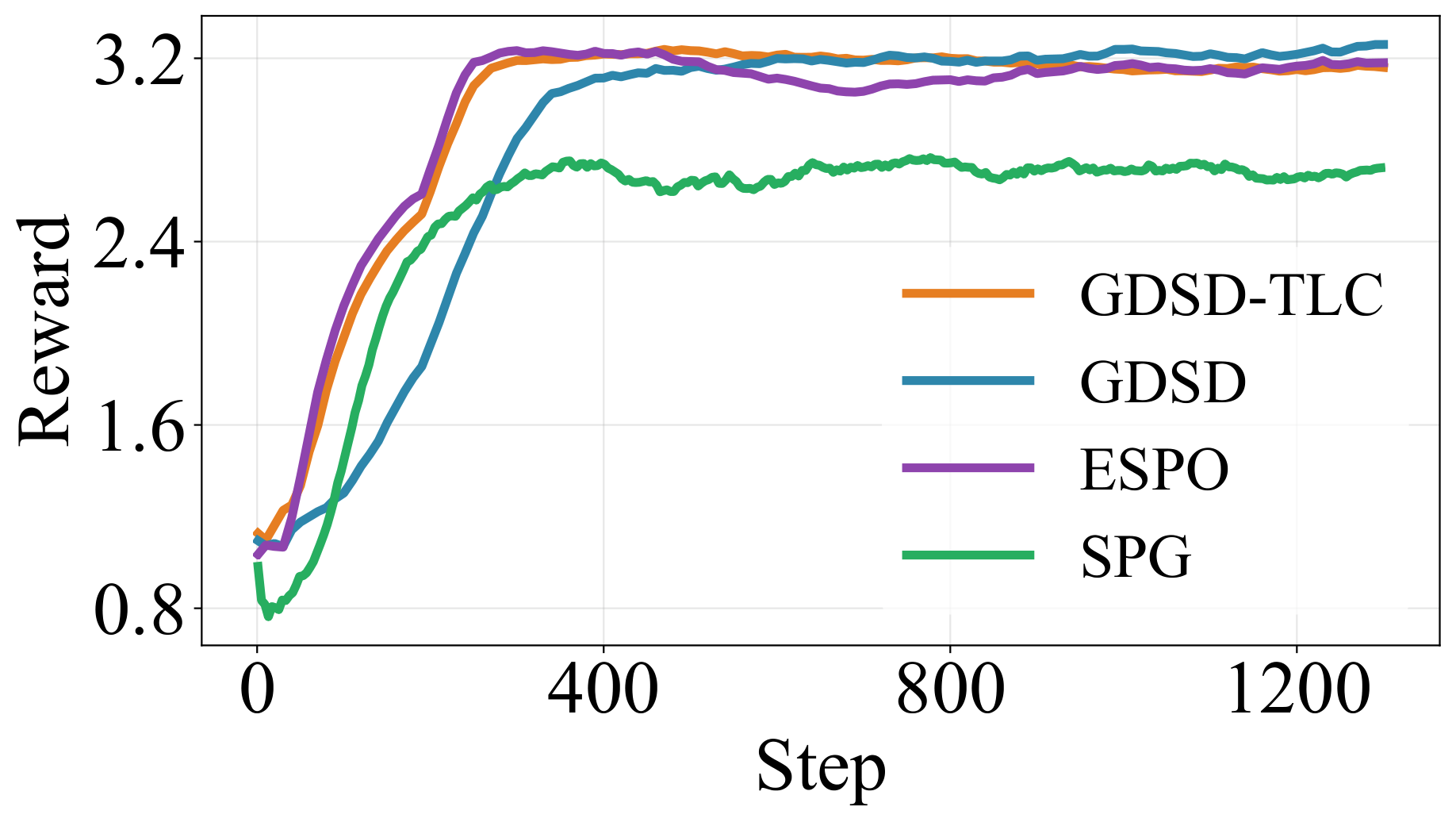
Our method GDSD obtains better test accuracy than ELBO-based methods.
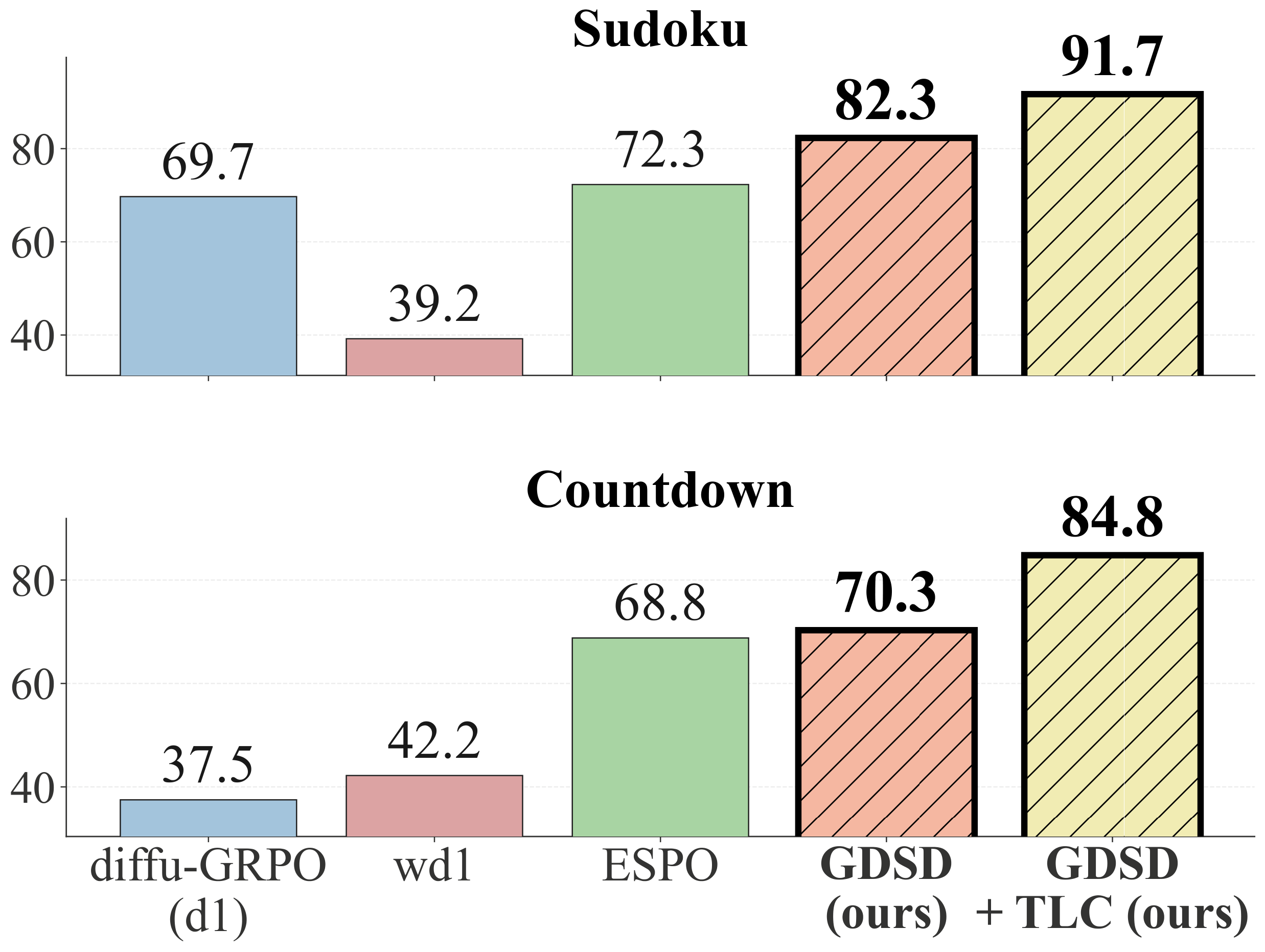
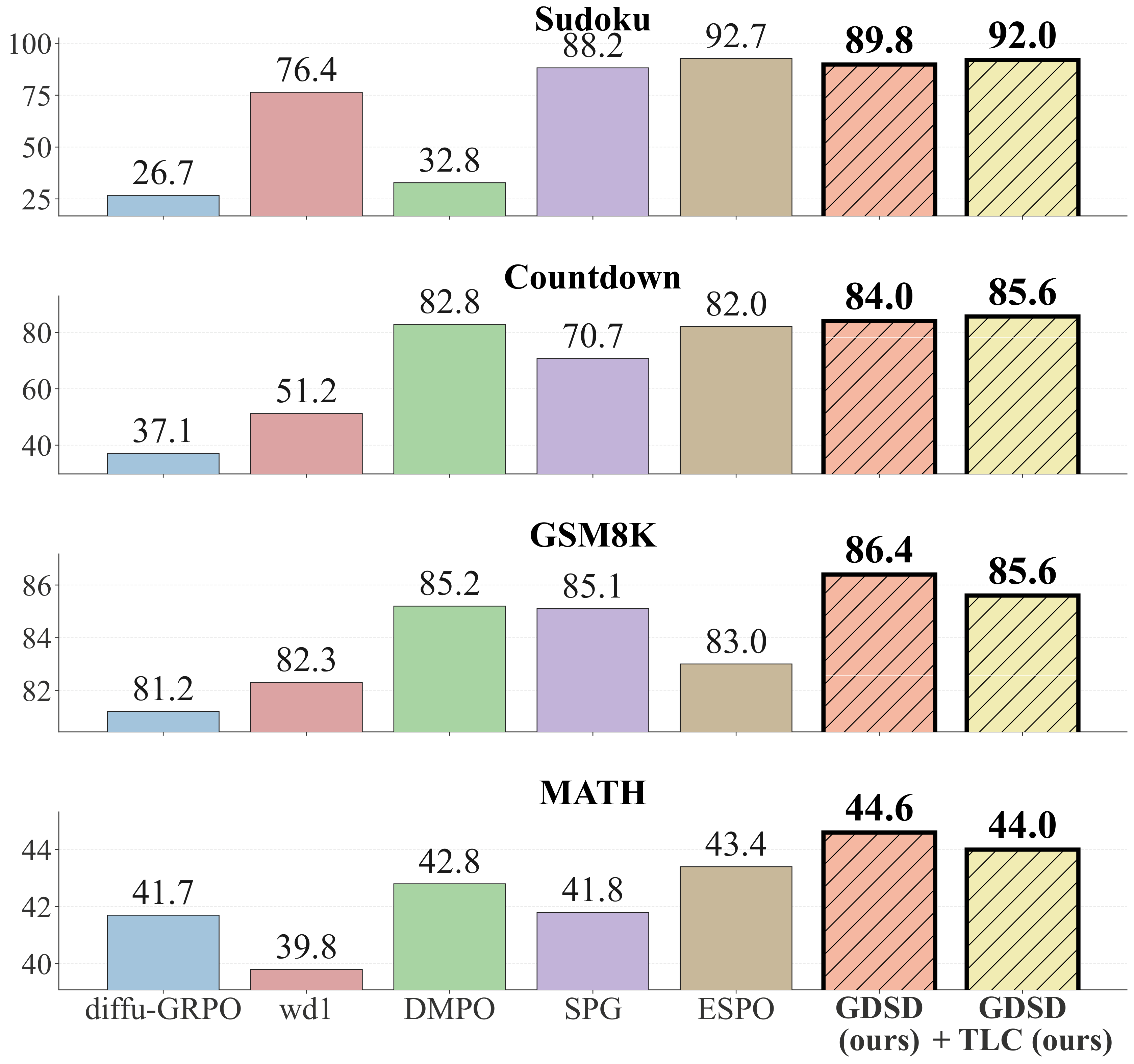
@misc{tang2026gdsdreinforcementlearningguided,
title={GDSD: Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion Language Models},
author={Xiaohang Tang and Keyue Jiang and Che Liu and Qifang Zhao and Xiaoxiao Xu and Sangwoong Yoon and Ilija Bogunovic},
year={2026},
eprint={2605.29398},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2605.29398},
}